Robot Intention Projection:
A Mixed-Reality Approach to Human-Robot Collaboration and Communication

VIDEOS OF INTENTION PROJECTION
REALTIME OBJECT TRACKING

PROJECTION MAPPING SYSTEM

EXTENSIBLE VISUAL LANGUAGE
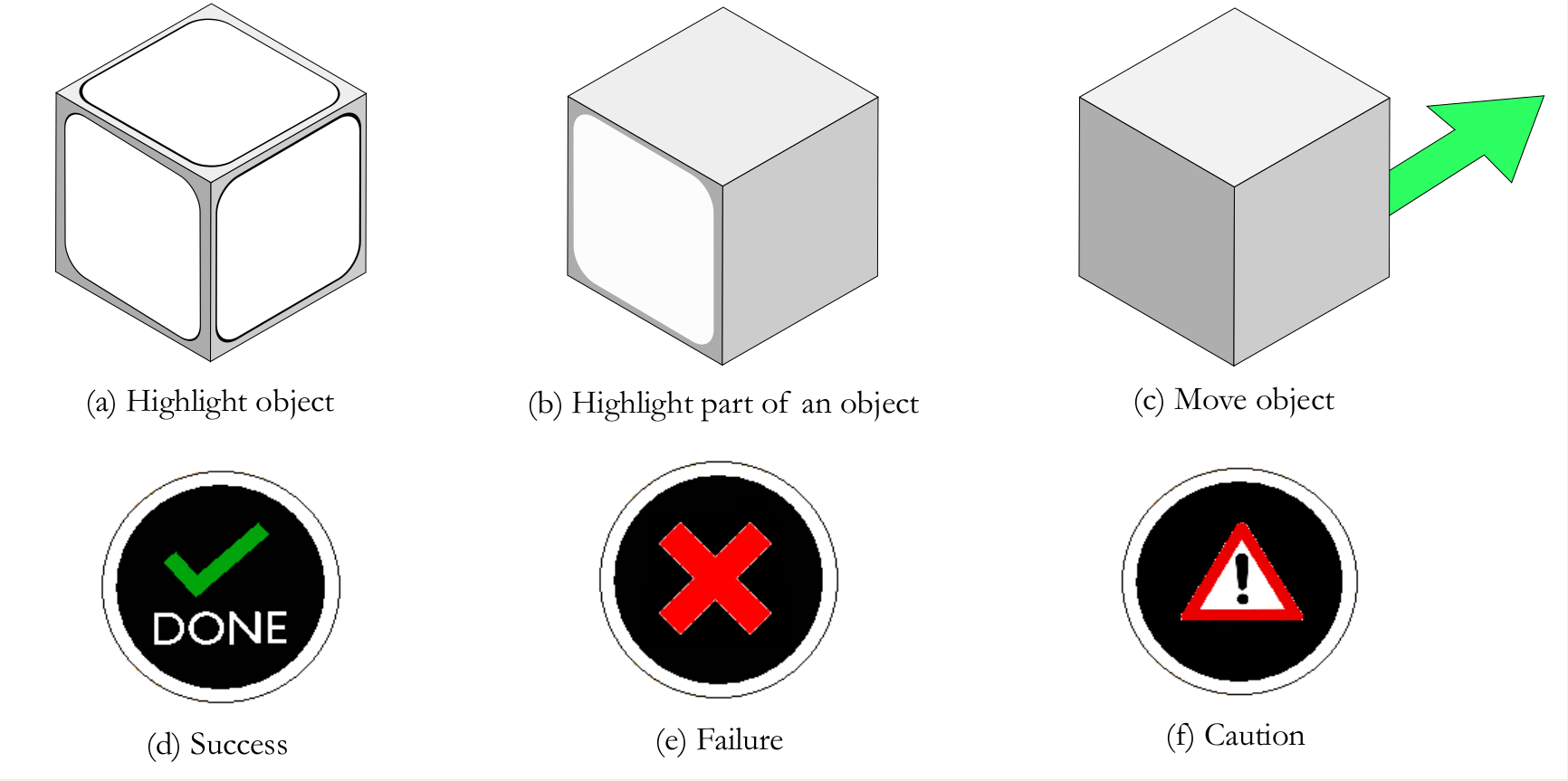
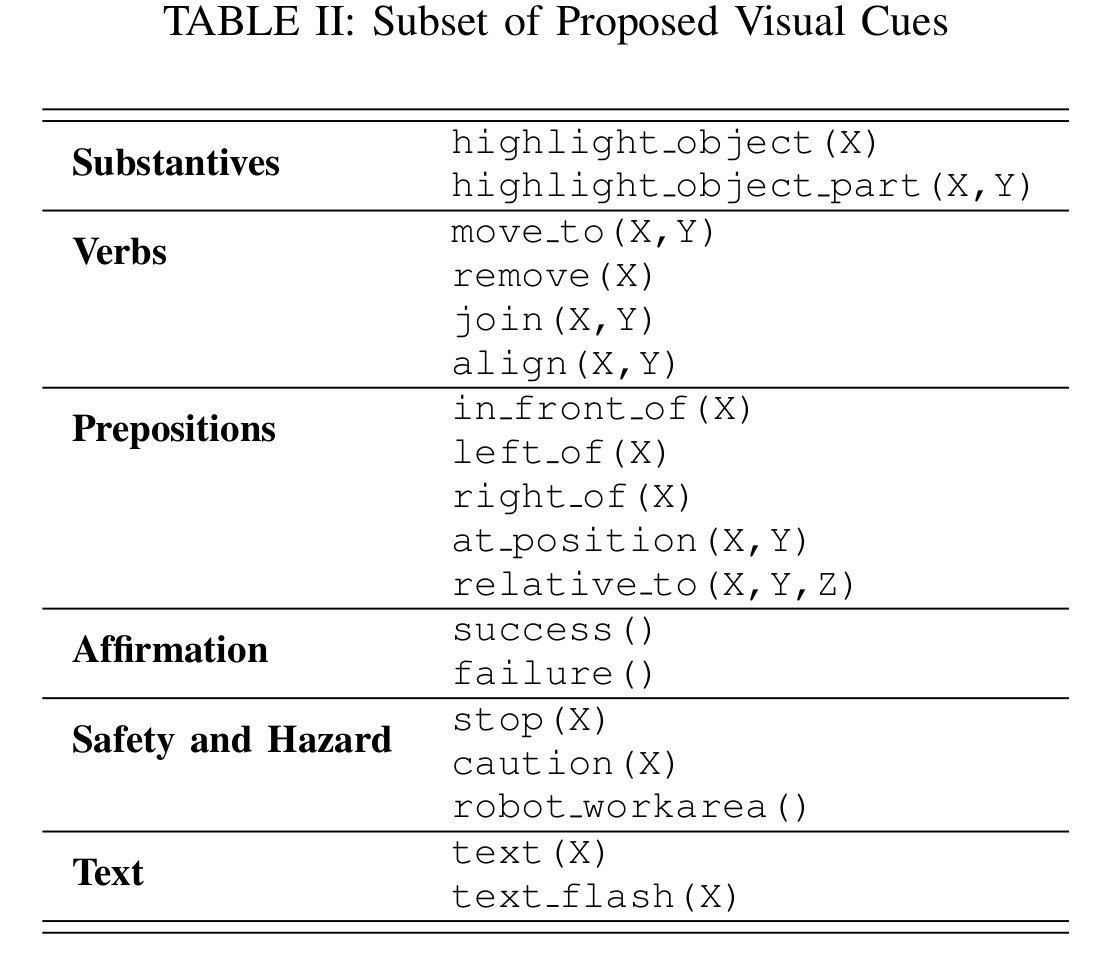
EXAMPLE SIGNALS AND INTERACTIONS

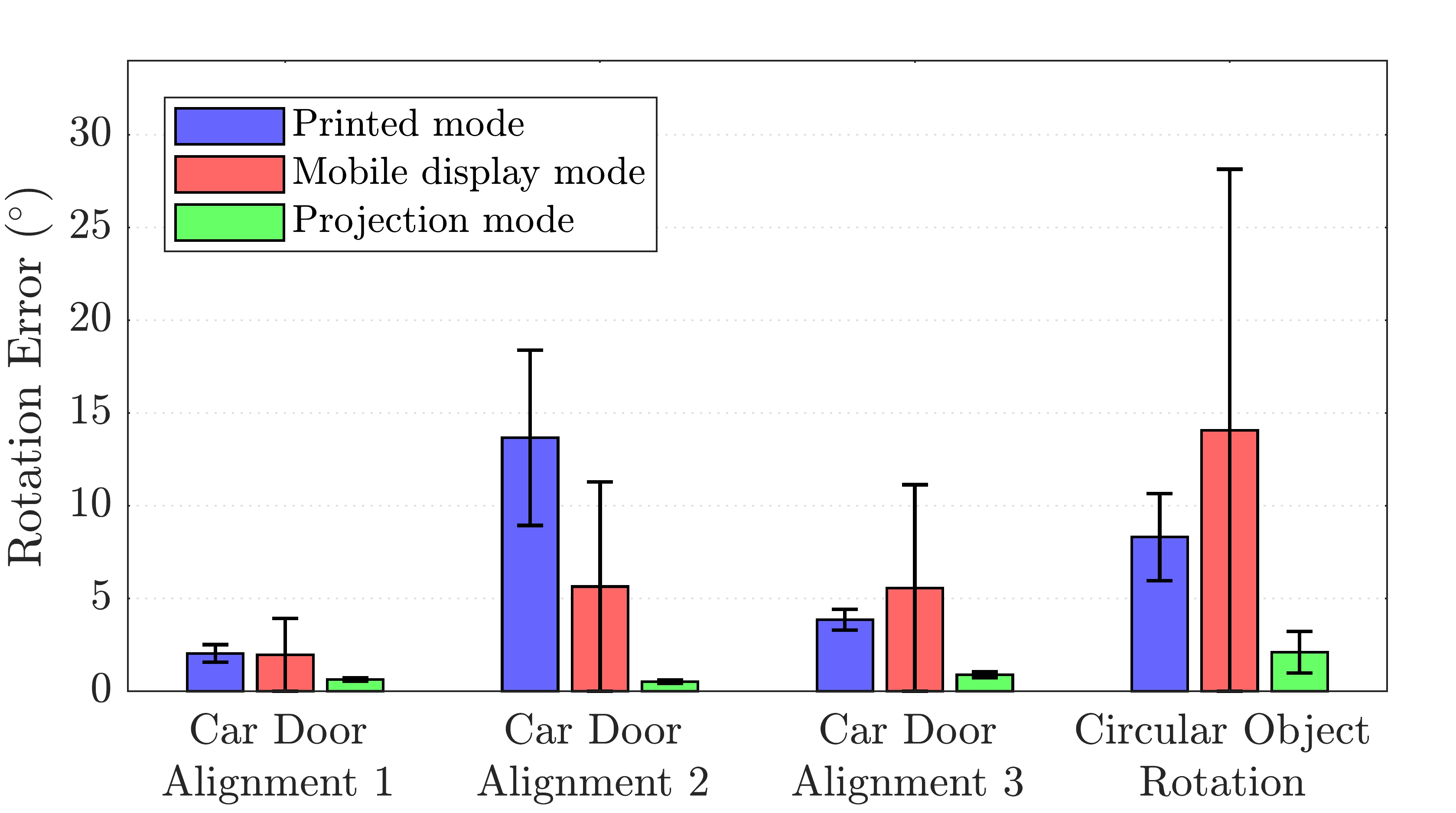
EXPERIMENTS AND RESULTS
Printed mode: The subjects were provided with a printed set of instructions in the form of written descriptions and corresponding figures. The printed instructions were pasted on a wall adjacent to the workspace and were available to the subject throughout the experiment.
Mobile display mode: The subjects were provided with a tablet device consisting of instructions in the form of texts, figures, animations and videos. The device was free to be carried around while executing the task. Instructions were provided just-in-time via “forward” and “backward” buttons that allowed users to move to the next or previous tasks.
Projection mode: The subject was provided with just-in-time instructions by augmenting (using projection mapping) the work environment with mixed reality cues.

PAPER AND REFERENCES
Cite: If you use this library, please use this citation:
@article{ganesan2018better,
title={Better teaming through visual cues: how projecting imagery in a workspace can improve human-robot collaboration},
author={Ganesan, Ramsundar Kalpagam and Rathore, Yash K and Ross, Heather M and Amor, Heni Ben},
journal={IEEE Robotics \& Automation Magazine},
volume={25},
number={2},
pages={59–71},
year={2018},
publisher={IEEE}
}
Cite: If you use this library, please use this citation:
@inproceedings{andersen2016projecting,
title={Projecting robot intentions into human environments},
author={Andersen, Rasmus S and Madsen, Ole and Moeslund, Thomas B and Amor, Heni Ben},
booktitle={2016 25th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN)},
pages={294–301},
year={2016},
organization={IEEE}
}