IRL Collaborative Assembly Data Set
In this project, we present a new, publicly available multimodal dataset for collaborative industrial assembly between humans and robots. The novelty of our dataset is that it combines data from kinesthetic Programming by Demonstration with unstructured natural language descriptions. It is collected for a complex industrial assembly task, performed by multiple participants in an ongoing human subject study. Using verbal descriptions of the demonstrated task can greatly increase the efficiency of learning robot behaviors, and also leads towards natural collaborations by providing a convenient interface for human co-workers. We demonstrate a possible use-case for our dataset in a collaborative assembly scenario and discuss different analysis methods that extract cross-modal information about the task.
Download
You can download the data set at the following link: https://drive.google.com/drive/folders/1CnoWCK1V7ufQoqri3urDhtfib2t4E6YD?usp=sharing
The data set is available to download in two versions. We provide the ROS-Bags (ROS Lunar) as well as a post-processed version that is made available as SQLite3 databases.
Please note that we are still working on the data preparation and that the remaining data will be uploaded within the next weeks. The full data set will be available before IROS 2018.
Overview
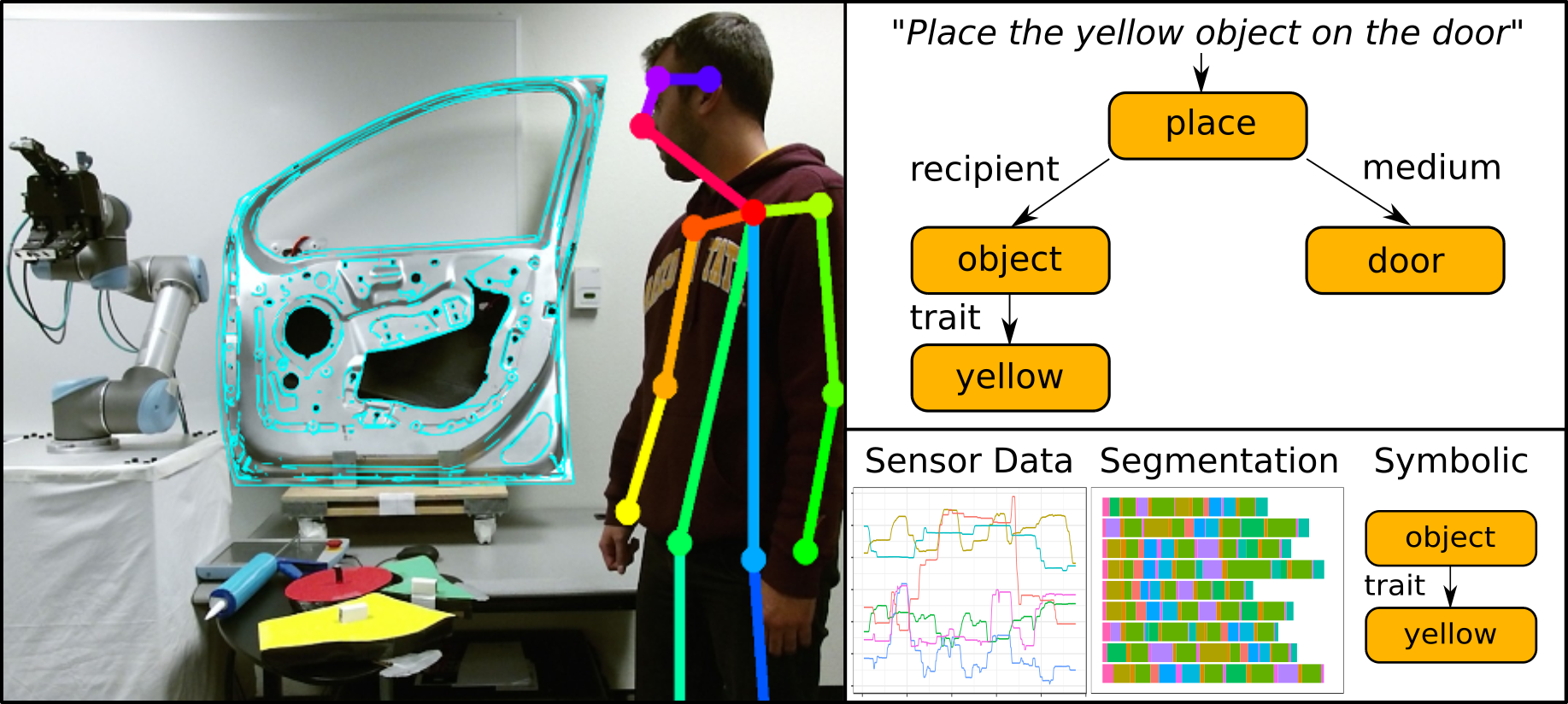
When thinking about the learning process of a human, we notice that a new skill is often taught by an expert who provides only a few demonstrations. However, such an expert (e.g. parent, teacher or sports coach) may also provide verbal directions and task descriptions that convey important information about the goals, objects, and intermediate actions. To go beyond existing approaches to PbD, it is important that robots leverage information from multiple data sources at the same time. Speech, movement, force, and timing of a human mentor may be combined with existing knowledge mined from linguistic and semantic corpora on the Internet to extract complex representations of the task that include symbolic and sub-symbolic components. Unfortunately, learning from multiple modalities, e.g. speech, force, and motion is extremely challenging and generally not well understood. Among the challenges towards multimodal PbD is the missing availability of public datasets that support the development and comparison of new algorithms.
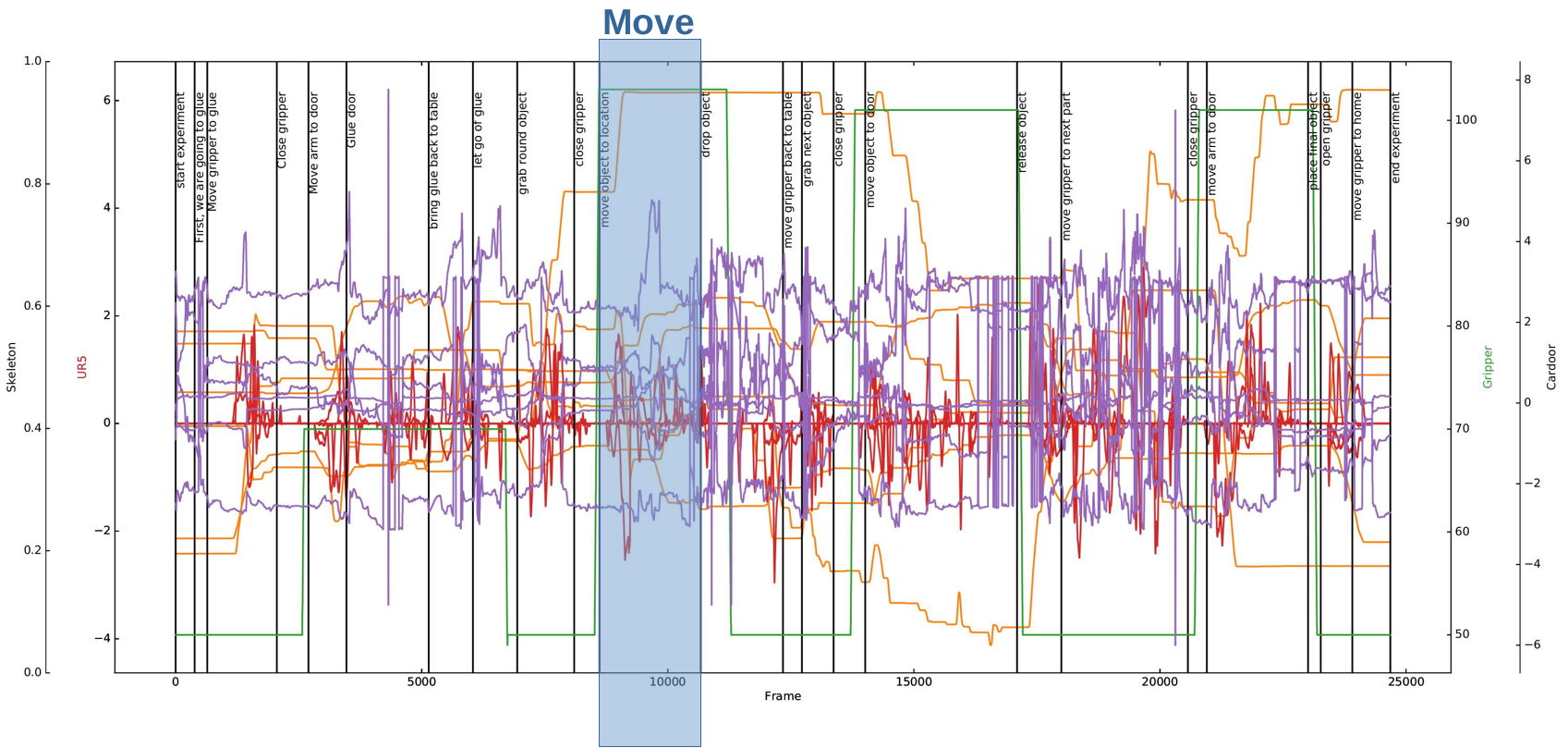
To overcome the above challenges, we propose a new, multimodal dataset of complex assembly procedures, containing a variety of lower-level sensor data along with higher-level, semantic information and verbal descriptions. The objective of collecting this data set is twofold: (1) recording a rich, publicly accessible data set for testing learning algorithms developed by the scientific community, and (2) understanding the variability that comes with multimodal instructions from a human teachers. The dataset contains raw video and depth data, object locations, skeleton tracking, and robot trajectories. Most importantly, the dataset is accompanied by transcribed, verbal task descriptions provided by multiple participants.