An Intelligent Robotic System for Retail: Multimodal and Machine Learning Approach
Investigators: Dr. Heni Ben Amor, ASU & Kailasnath Maneparambil, Intel Corp.
Students: Shubham Sonawani and Anand Kurapati
Techniques from Artificial Intelligence (AI) and Machine Learning (ML) are increasingly being used in the retail sector and have already proven to generate a substantial return-on-investment. Especially large retailers use the power of such methodologies to predict consumer spending, control their investments, and increase returns. However, the majority of current AI approaches only focus on information gathered from purchase and sales in order to make predictions and recommendations. Such approaches neglect the critical importance of the physical location of products, the geometric layout, and organization of the store, as well as typical movement patterns of the customers. One approach to do this is to create a planogram; a visual depiction that shows the placement of every product in the store. Such planograms can be very expensive and time- consuming in their creation. Most importantly, however, they are notoriously hard to maintain on a frequent basis, since this requires the store to be inventoried by human workers. In this project, we propose a robotic real-time inventory system that can generate such planograms.

Depth Prediction Framework
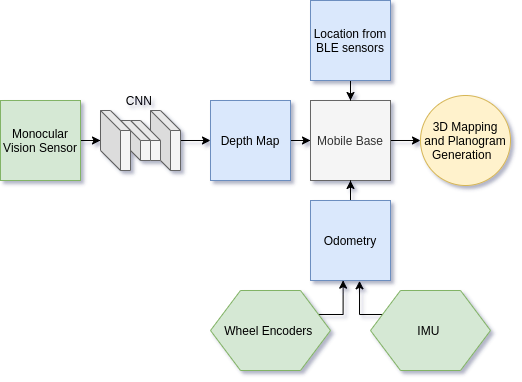
The first component in our system is a depth prediction network that generates per-pixel depth estimates of the environment. Our specific neural network architecture consists of an encoder-decoder network with skip connections between the encoder and decoder layers. Bilinear upsampling is used in the decoder to generate increasingly higher-resolution versions of the depth estimate. The loss function used in training combines the pixel wise Euclidean norm between predicted and ground truth depth maps, the Euclidean norm of the gradient of predicted and ground truth depth maps, and finally the structural similarity loss between the two images. The overall accuracy of our network on test data is approx. 91% . See the demo below for depth prediction in action.

Here is another example showcasing depth prediction using different colormap.
Predicted depth map can be used to generated high level information of environment such as 3D map. See below demo of 3D map generation using RtabMap and predicted depth.
System Architecture
System mainly consist of following components:
- Mobile Base
- Consist of on-board core i5 CPU
- 32 GB ROM and 8 GB RAM
- Onboard IMU and Wheel Encoder (Provide Odometry Data)
- Monocular Vision Sensor
- Global Shutter Vision Sensor
- Resolution: 640×480, 1280×720
- Manipulator
- Custom designed 6 DoF manipulator
- Dockerized API
- Easy portability
Simulation Framework
We leverage open source Robot Operating System (ROS) and Physics Simulator (Gazebo) to test and improve the algorithms assisting in grasping and manipulation tasks. Our system features a modern, yet affordable, robot arm. The arm has 6 degrees-of-freedom and features both position control and velocity control. We have developed and provided the full URDF model of the arm along with an inverse kinematics solution that can be accessed via the Robot Operating System (ROS). In addition to inverse kinematics, our controller includes Dynamic Motor Primitives (DMPs), which can be learned from human training data. Instead of writing low-level control code, the human expert only needs to provide examples of the expected movement of the robot. We can automatically extract a DMP from these examples. In addition, the DMPs generalize the trained movement to new situations, e.g., the object moved to a different location.
Bluetooth Low Energy Localization Framework
In order to combine multiple point clouds into a map, traditional localization and mapping techniques and iterative closest-point methods can be used. Unfortunately, this often comes with substantial parameter tweaking and calibration which is a hindrance to robotic systems. We overcome this challenge by leveraging BLE sensors. In particular, we placed around 4 BLE sensors randomly in the workspace of the robot. These sensors can be acquired at extremely low-costs and do not require any calibration. The relative distance to each beacon can be deduced from the signal strength. A more complex operation can be used to calculate the relative orientation of the robot wrt. each beacon. Both sensor readings are, in turn, are used within an Extended Kalman filter to estimate the position and orientation of the robot in space. These positions are used as initial locations for the individual point clouds generated in the process described above, which are then refined through optimization techniques. Hence, larger maps of the environment can be obtained by leveraging both sources of information. IMU and wheel encoder data is also used within the localization process. Data from the BLE sensors is obtained and updated at a rate of 10 Hz. Demo of localization using BLE sensors is implemented as phone application too. Please see video below for app demo.

Publications and Presentations
-
Multimodal Data Fusion for Power-On-and-Go Robotic Systems in Retail
Robotics Science and Symposium (RSS) 2020: Power on and Go workshop (paper)
-
An Intelligent Robotic System in Retail: Machine Learning Approach
International Sysmposium on Artificial Intelligence and Brain Science, Tokyo, Japan (poster coming)
Videos
Live demonstration at Southwest Robotics Symposium 2019
Our robot was nationally featured on CBS NEWS and was also featured in 196 local CBS affiliates from San Diego to New York. It was also live demonstrated at the 2019 Southwest Robotics Symposium. Checkout the video shown below for more details.
Code and Repositories
Highlights
ACKNOWLEDGMENTS AND FUNDING
Funding for this project is provided by a grant from Intel. We would like to thank our sponsor for their generous support and for the ongoing collaborations with Arizona State University.